Le FOS et l'inférence.
Piloter par les probabilités, pas par les moyennes.

L’inférence statistique : la couche d'interprétation statistique qui transforme des métriques descriptives en signaux décisionnels. Un article technique, assumé comme tel.
Il y a une faille dans tous les systèmes de pilotage par métriques … y compris le FOS tel que je l’ai décrit jusqu’ici. Cette faille est silencieuse, et c’est précisément pour ça qu’elle est dangereuse.
La voici : toute métrique de flux varie naturellement. Le lead time n’est pas une constante : c’est une distribution. Le WIP fluctue. La flow efficiency oscille. Ces variations sont inhérentes à tout système complexe. Elles ne signifient pas forcément que quelque chose va mal.
Mais sans cadre d’interprétation statistique, on ne sait pas distinguer une fluctuation normale d’un signal réel de dégradation ou d’amélioration. On sur-réagit à du bruit. Ou, plus souvent, on ignore un signal faible jusqu’à ce qu’il devienne une crise visible.
Une moyenne qui reste stable peut cacher une variance qui explose. Un système peut se dégrader pendant des semaines avant que sa moyenne ne bouge. C’est précisément ce que les tableaux de bord classiques ne voient pas.
Cet article introduit la couche d’interprétation probabiliste du FOS. Ce que j’appelle la Flow Intelligence Layer. Elle ne remplace pas les métriques descriptives. Elle les rend actionnables en répondant à la vraie question décisionnelle : ce que j’observe est-il statistiquement significatif, ou dois-je attendre davantage de données avant d’agir ?
Le problème fondamental : piloter avec des moyennes
Prenons un exemple concret. Votre lead time end-to-end est mesuré chaque semaine depuis six mois. Voici une séquence typique :
Semaine 1 : 9,2 semaines
Semaine 2 : 10,1 semaines
Semaine 3 : 9,8 semaines
Semaine 4 : 11,4 semaines
Semaine 5 : 10,7 semaines
Semaine 6 : 12,1 semaines
Semaine 7 : 11,8 semaines
Semaine 8 : 12,9 semaines
Moyenne des 4 premières semaines : 10,1 semaines. Moyenne des 4 dernières : 12,1 semaines. Écart : +2 semaines, soit +20 %.
Est-ce une dégradation réelle ou une fluctuation normale ? Sans inférence statistique, vous ne pouvez pas répondre à cette question avec rigueur. Vous pouvez avoir une intuition. Vous pouvez débattre en réunion. Mais vous ne pouvez pas décider avec une base probabiliste solide.
C’est le problème des tableaux de bord classiques : ils montrent des valeurs. Ils ne disent pas si ces valeurs sont significatives. La décision “agir ou attendre” reste alors une affaire d’intuition habillée en données.
Les trois outils statistiques fondateurs
La Flow Intelligence Layer du FOS repose sur trois outils statistiques. Ils ne nécessitent pas de formation avancée en statistiques pour être compris et utilisés mais ils nécessitent d’être introduits explicitement dans le système de pilotage.
1. Les Control Charts (cartes de contrôle)
Le control chart (ou carte de contrôle de Shewhart) est l’outil le plus puissant et le plus sous-utilisé dans le pilotage du flux. Il permet de distinguer visuellement deux types de variation :
La variation commune (bruit) : les fluctuations inhérentes au système, prévisibles, qui ne nécessitent pas d’intervention. Tenter de corriger du bruit est l’une des erreurs les plus coûteuses en management. Deming l’appelait « tampering ».
La variation spéciale (signal) : une variation qui sort du comportement normal du système, statistiquement improbable, qui indique qu’un facteur externe a changé. C’est ça qui nécessite une action.
Un control chart se construit simplement sur une série de mesures de lead time :
Moyenne (μ) : calculée sur la période de référence
Limite de contrôle supérieure : μ + 3σ
Limite de contrôle inférieure : μ - 3σ
Règle de base : tout point hors des limites = signal. On arrête. On cherche la cause.
Règle secondaire : 8 points consécutifs du même côté de la moyenne = dérive. Signal.
Dans notre exemple précédent, un control chart aurait révélé dès la semaine 6 que la trajectoire constituait une dérive statistiquement significative, pas parce que la valeur a dépassé une limite absolue, mais parce que le pattern de 5 points consécutifs au-dessus de la moyenne est statistiquement improbable sous l’hypothèse d’un système stable.
Avant : Notre lead time est passé de 10 à 12 semaines. C’est préoccupant.
Avec inférence : Notre control chart indique une dérive significative depuis la semaine 5 : 5 points consécutifs au-dessus de la moyenne historique. La probabilité que ce soit du bruit est inférieure à 3%. Nous activons le Playbook Dérive de Lead Time. (Et pour que tu découvre en profondeur les playbooks… il faudra attendre encore un poil ;) )
2. Les intervalles de confiance
Une métrique sans intervalle de confiance est une information incomplète. La moyenne du lead time à 10,1 semaines ne dit rien sur la fiabilité de cette estimation ni sur la variabilité du système.
L’intervalle de confiance à 95 % répond à une question précise : si on tire un nouvel échantillon de la même population, dans 95 % des cas la vraie valeur sera dans cet intervalle. C’est une mesure d’incertitude… et l’incertitude est une information décisionnelle à part entière.
Lead time moyen : 10,1 semaines
Écart-type : 1,2 semaines
n (nombre de mesures) : 20
Intervalle de confiance : 10,1 ± 0,54 → [9,56 ; 10,64]
Interprétation : on est à 95% certain que le vrai lead time moyen du système est entre 9,56 et 10,64 semaines.
Pourquoi c’est “décisionnellement” important ? Parce que deux systèmes avec le même lead time moyen peuvent avoir des intervalles de confiance très différents. Un système avec IC [9,5 ; 10,7] est prévisible. Un système avec IC [6 ; 14,2] est chaotique — même si la moyenne est identique. La décision d’investir, de scaler, ou d’alerter doit intégrer cette information. C’est pourquoi il est aussi souvent préférable d’utiliser la médiane comme nous allons le voir plus bas.
Avant : Notre lead time moyen est de 10 semaines.
Avec inférence : Notre lead time est de 10 semaines ± 2,1 (IC 95%). L’intervalle s’est élargi de 40% ce trimestre, ce qui indique une instabilité croissante du système indépendamment de la moyenne.
3. Les percentiles de distribution
La moyenne est une mesure trompeuse dans les systèmes à longue queue ce que sont presque tous les systèmes de flux de valeur. Une minorité d’items avec un lead time très long tire la moyenne vers le haut et masque la réalité de la majorité.
Les percentiles donnent une image bien plus fidèle :

Le P85 est particulièrement utile pour les engagements clients : si vous prometttez une livraison en 14 semaines, vous tiendrez cet engagement dans 85% des cas. C’est un niveau de confiance explicite bien supérieur à un engagement basé sur la moyenne qui, par définition, est dépassée dans la moitié des cas.
Les Playbooks du FOS peuvent ainsi utiliser le P95 comme seuil de déclenchement : si la durée observée d’une dépendance dépasse le P95 historique, on active l’escalade pas avant, pas après.
Avant : Si la dépendance dure plus de 10 jours, on escalade.
Avec inférence : Si la durée de la dépendance dépasse le P95 historique (actuellement 9,3 jours), on active le Playbook Escalade. Le seuil se recalcule automatiquement chaque trimestre.
Comment enrichir chaque composante du FOS
Le Kernel probabiliste
Le Kernel classique (décrit dans le 2nd article de cette série) pose des règles absolues : « on ne lance pas si le WIP dépasse N ». C’est nécessaire et non négociable. Mais ces seuils sont souvent fixés de façon arbitraire, par intuition ou par consensus.
La couche probabiliste permet de calibrer ces seuils sur des données historiques réelles. Le seuil de WIP n’est plus un chiffre round négocié en atelier. C’est le seuil au-delà duquel la probabilité d’augmentation du lead time dépasse un niveau de risque accepté … par exemple 60 %.
Règle Kernel classique : WIP ≤ 12 initiatives actives
Règle Kernel enrichie : WIP ≤ seuil au-delà duquel
P(lead time > 14 semaines) > 60%
[recalibré chaque trimestre sur données réelles]
Ce que ça change : le seuil devient défendable face à un CFO ou un CEO. On ne dit plus « on a décidé que 12 c’était le maximum ». On dit « au-delà de 12, nos données montrent que le risque de dépasser nos engagements clients devient inacceptable ». C’est une conversation différente.
Les Loops décisionnelles
Dans une Loop Portfolio classique, la décision de lancer ou d’arrêter une initiative repose sur des arguments qualitatifs : valeur stratégique, urgence, pression des sponsors. Ces arguments sont légitimes. Ils deviennent bien plus robustes quand ils sont complétés par une évaluation probabiliste du risque systémique.
Question Loop Portfolio classique :
→ Cette initiative est-elle prioritaire ?
Question Loop Portfolio enrichie :
→ Quelle est la probabilité que le lancement de cette initiative augmente notre lead time moyen de plus de 20% ce trimestre ?
[basée sur le WIP actuel, la capacité disponible, les dépendances connues]
Cette question n’est pas rhétorique. Elle est calculable approximativement, avec des données historiques de quelques trimestres. Et elle transforme le débat d’opinion en discussion de risque. Un CPO qui dit « je pense qu’on peut absorber ce projet » est challengeable. Un modèle qui dit « la probabilité de dégradation est de 73% » est discutable sur ses hypothèses … ce qui est une conversation bien plus productive.
La Scorecard comme instrument scientifique
C’est la transformation la plus visible. Une Scorecard classique affiche des valeurs ponctuelles. Une Scorecard enrichie par l’inférence affiche des distributions, des tendances statistiquement qualifiées, et des signaux d’alerte fondés sur des probabilités.
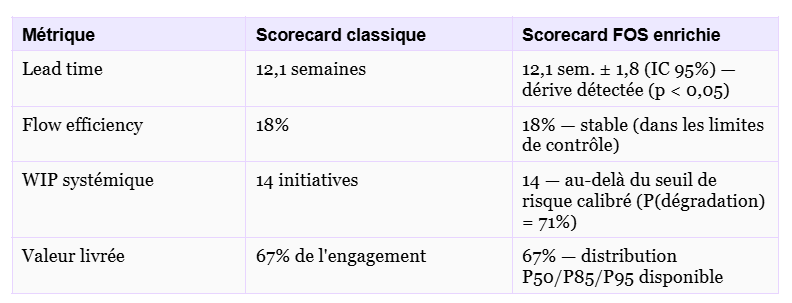
La différence n’est pas cosmétique. Elle change ce qu’on peut décider. La première ligne du tableau dit : « le lead time a augmenté ». La deuxième dit : « le lead time a augmenté et c’est statistiquement significatif la probabilité que ce soit du bruit est inférieure à 5% ». Ce n’est pas la même décision.
Les Playbooks à déclenchement statistique
Aujourd’hui, les Playbooks se déclenchent sur des règles de seuil absolues, par exemple une dépendance depuis N jours, un WIP au-dessus de M. Ces seuils sont utiles mais rigides. Ils ne s’adaptent pas à la variabilité historique du système.
Un Playbook à déclenchement statistique se déclenche quand une observation est statistiquement anormale par rapport à l’historique du système, pas par rapport à un seuil arbitraire. C’est plus robuste, moins émotionnel, et plus difficile à contourner politiquement.
Playbook Dépendance — version classique :
→ Déclenchement si durée > 10 jours
Playbook Dépendance — version statistique :
→ Déclenchement si durée > P95 historique des dépendances résolues
ET si control chart indique un point hors limites
[Le seuil se recalibre automatiquement chaque trimestre]
Ce que ça change philosophiquement
Les articles précédents de cette série posent une affirmation centrale :
Le flux ne se décrète pas. Il se pilote.
La couche probabiliste enrichit cette affirmation d’une précision fondamentale :
On ne pilote pas un système complexe avec des moyennes. On pilote avec des probabilités.
Ce n’est pas un détail technique. C’est un changement épistémologique. Un système complexe (et une organisation est un système complexe) ne se comporte pas de façon déterministe. Il se comporte de façon probabiliste. Ses métriques sont des distributions, pas des points. Ses tendances sont des signaux à qualifier, pas des faits à constater.
Ignorer cette réalité, c’est piloter un avion en regardant une photo de l’altitude plutôt qu’un altimètre avec une marge d’erreur. L’information est là. L’incertitude est masquée. Et c’est l’incertitude qui tue.
Par où commencer concrètement
Introduire l’inférence statistique dans un système de pilotage ne nécessite pas de refondre tout le dispositif. Voici une séquence progressive :
Étape 1 : Construire un control chart sur le lead time. C’est le ROI le plus rapide. Prenez vos données de lead time des 3 derniers mois, calculez la moyenne et l’écart-type, tracez les limites de contrôle à ±3σ. Regardez si des points en sortent. Si oui, vous avez votre premier signal statistique réel.
Étape 2 : Introduire les percentiles dans vos engagements. Remplacez « on livrera en moyenne en 10 semaines » par « on livre en moins de 13 semaines dans 85% des cas ». C’est plus honnête, plus utile pour les partenaires, et plus robuste quand vous êtes challengé.
Étape 3 : Ajouter les intervalles de confiance à la Scorecard. Une ligne de plus par métrique. L’impact sur la qualité des discussions en Loop Portfolio est immédiat.
Étape 4 : Recalibrer les seuils du Kernel sur données réelles. Remplacez vos seuils arbitraires par des seuils calculés à partir de votre historique de flux. C’est un travail d’une demi-journée par trimestre. C’est aussi la conversation la plus productive que vous aurez avec votre équipe de direction.
Aucune de ces étapes ne nécessite un data scientist. Elle nécessite un tableur, des données historiques, et une culture organisationnelle prête à piloter par les probabilités plutôt que par les certitudes confortables.
La vraie sophistication n’est pas de produire des modèles complexes. C’est d’avoir le courage institutionnel de dire : nous ne savons pas avec certitude … et voici ce que les données nous permettent de dire avec 80% de confiance.